
Cracking Captchas with Keras and R
Overview
Remember these things?
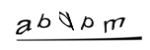
You don't really encounter these out in the wild these days. Why? With recent (recent to me!) advances in machine learning, cracking these captchas has become somewhat trivial for a computer. Even someone who has been out of the game for a while can solve this problem.
Please note this page require javascript to be enabled as the images are being processed each time this page is reloaded.
Here are some examples:
| Image | Actual | Predicted | Match |
|---|---|---|---|
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
|
xxxxx | xxxxx | xxxx |
You should see 7 or 8 successes, which matches the validation accuracy of about 80%. Is this good enough? In our case, Yes! As a general rule, you are not penalized for failure to guess correctly on the first pass. Since I do not incur a huge penalty for a failure I can just try again. At 80% accuracy I have a \((0.8 + 0.2*0.8) = 96\)% chance of getting it right in 2 tries or less and \((0.8 + 0.2*0.8 + 0.2^2*0.8) = 99.2\)% in 3 tries or less. Given it is expected a human will fail a captcha with a non-zero probability, multiple attempts are allowed.
Method
To get started, I had to generate the data set. I used the Python library Claptcha to generate captchas with 5 characters. I generated about \(2 * 10^5\) images to use as a training dataset and \(5 * 10^3\) images to use for validation. The true label was simply stored in the filename. With 5 characters there are \(26^5\) possible outputs. In our training data set there is a \((2*10^5) / 26^5 = 1.683\)% chance of duplicate images. I consider this small enough to ignore. Finally a separate test set was generated for use on this website which the model never saw in training or validation.
As with most image recognition tasks, I used a convolutional neural network (CNN) with a final dense layer. One of the most interesting features of NN architecture is that I can easily specify multiple inputs or outputs for my model. In this case there is a single input, the image, and 5 outputs, the predicted characters that correspond to each character. The final model is not significantly different from a model trained to solve a simple MINST-like problem but rather than a single node output, there are 5 outputs. Instead of a single 1-hot encoded vector of length 26, the model outputs five 1-hot encoded vectors of length 26. This means I am predicting 5 characters independently of each other. I do not have to use bounding boxes to indicate the location of the characters which makes generating additional data trivial.
Lessons Learned
Selecting hyperparameters turns out to be an important step that can be the difference between a model with 80% accuracy and a complete failure to learn. This means that many models will need to be tested. A GPU is a requirement.
Independent error propagates quickly. While I could achieve about 96% accuracy per character, the final sequence has \(0.96^5 = 81.5\)% accuracy. If I were trying to recognize text, I could included a language model that would incorporate the statistical nature of letter sequences, for example Q is likely followed U. But in this case, the letters are random and so there is no information provided by the other characters.
Memory management is critical as my GPU only has 8 gigs of memory. I am not sure why a 150mb data set ends up using 8 gigs of memory. I will have to investigate this further.
While R is my language of choice, the Keras implementation is using the Reticulate package to call python functions. This is great if there are only a few python function to call, for example calling the Clapthca function to generate images, but it becomes a little less clear what the benefit is when using a large library like Keras. I'll probably always prefer base R plots syntax to matplotlib though.
Even though I did this project in R, I had to manage my Python environments. Learn to love Conda. It will save you so much time and effort. Setting up TensorFlow to work with my GPU was a breeze- a simple conda install -c anaconda tensorflow-gpu and if you don't have a GPU make sure you get a version of TensorFlow that uses all your CPU's instruction sets. Do this with conda as well.
Very early on it became apparent using a single thread was not going to be ideal. Make sure your code takes advantage of multicore processors. This was pretty easy to setup in R using doMC.
Possible Improvements
I restricted my problem set to cases of 5 characters but this would not necessarily be true of captchas in the wild. One way to deal with this is to add an RNN layer in between the final CNN layer and final dense layers. This should allow the model to also predict sequences of arbitrary length by also predicting the number of characters as well as each character.
I also only used a single font. For a more general solution I would need to generate more captcha images with different fonts.
Conclusion
It should be clear now that captchas do not identify humans. A machine can easily solve this problem just as well as a human can and so therefore serve no purpose.